Reading path
Before detailing the cache working, we have to dig in reading path :
First, two drawing (from datastax website) to represent it :
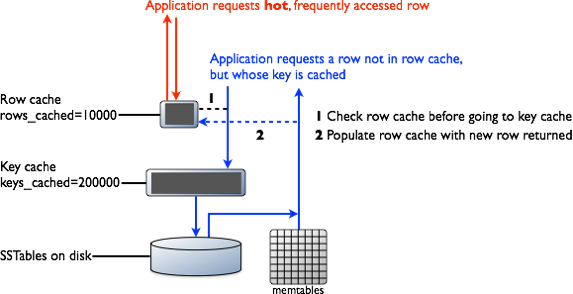
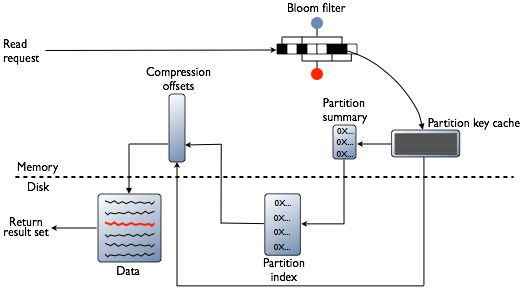
So what I understand :
- Checks if the in-memory memtable cache still contain the data (if it is not yet flushed to SSTable)
- If enabled, row cache
- BloomFilter (for each SSTable)
- Key cache
- Partition Summary
- SSTables
A generic diagram that (I hope) summarize !
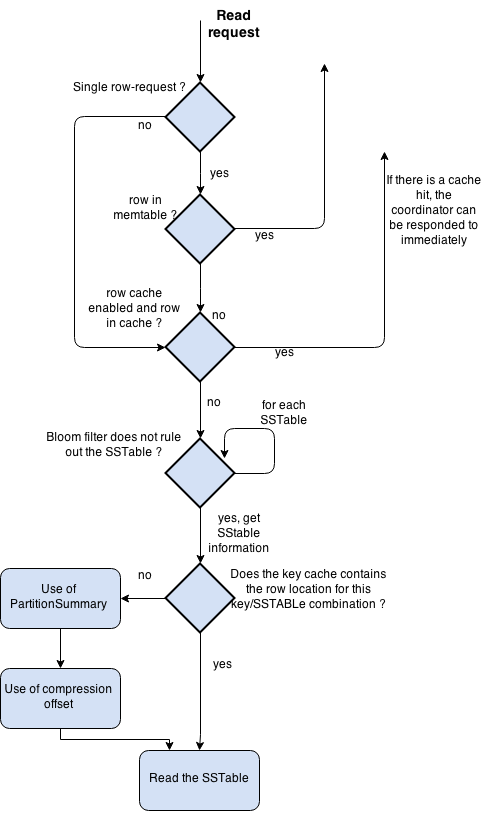
A little vocabulary
SSTable
SSTables are immutable, not written to again after the memtable is flushed. Thus, a partition is typically stored across multiple SSTable files.
For each SSTables, cassandra create one Partition Index, Partition Summary and BloomFilter
Memtable
When a write occurs, Cassandra stores the data in a structure in memory, the memtable, and also appends writes to the commit log on disk. The memtable stores writes until reaching a limit, and then is flushed.
Cassandra flushes memtables to disk, creating SSTables when the commit log space threshold has been exceeded
Partition Index :
A list of primary keys and the start position of data
Partition summary
A subset of the partition index (in memory). By default, 1 partition key out of every 128 is sampled.
Caches
Row cache :
The row cache is similar to a traditional cache like memcached. When a row is accessed, the entire row is pulled into memory, merging from multiple SSTables if necessary, and cached, so that further reads against that row can be satisfied without hitting disk at all.
While storing the row cache off-heap, Cassandra has to deserialize a partition into heap to read from it, so we have to take care about partition size.
The row cache is not write-through. If a write comes in for the row, the cache for it is invalidated and is not be cached again until it is read again.
BloomFilter :
Not really a cache, Cassandra uses Bloom filters to determine whether an SSTable has data for a particular row.
The bloom_filter_fp_chance setting allow to trade memory for accuracy, Bloom filter settings range from 0 to 1.0 (disabled). The more bloom_filter_fp_chance the less memory it used.
The default value of bloom_filter_fp_chance depends on the compaction strategy and is a table’s property (LeveledCompactionStrategy => 0.1, SizeTieredCompactionStrategy and DateTieredCompactionStrategy => 0.01),
this could be explain by the fact that LeveledCompactionStrategy
Bloom filters are also stored in off-heap memory.
Key Cache :
The partition key cache is a cache of the partition index for a Cassandra table. It allow to find if the node contains or not the needed row.
It is activated by default.
Reference to key cache configuration
The partition key cache is a fixed size and is stored in off-heap memory.
Thus, if all node contains all datas (Number node = RF), there is a gain to use key cache ?
In memory Table (DSE only)
It is defined at table level with table metadata ‘class’: ‘MemoryOnlyStrategy’.
The rows are kept in heap memory.
See DSE documentation for more detail